The useful version of background agents is not just an agent running while nobody is watching.
That is the easy misunderstanding. Put a model in another terminal, let it run for longer, and call it a background agent. The idea sounds bigger than it is.
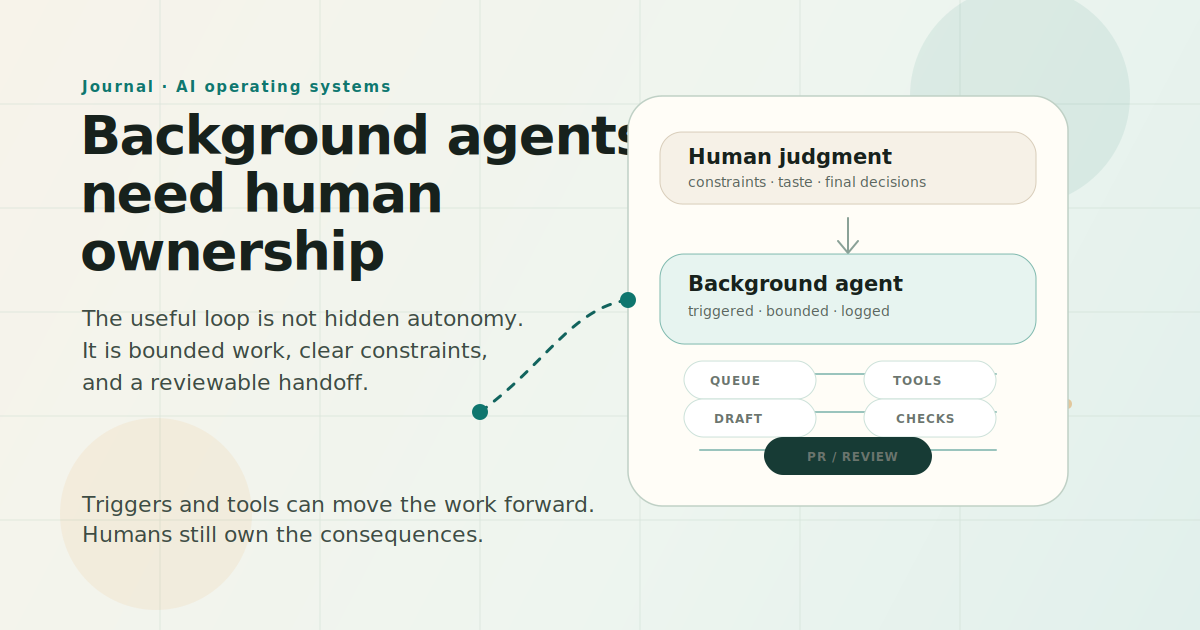
The more interesting version is closer to operating infrastructure. A trigger starts the work. A queue defines what is eligible. Permissions limit the tools. Logs show what happened. The output is something a person can review, often a pull request, a draft, or a structured report. The agent may do the work in the background, but the system around it decides whether that work is safe, useful, and worth attention.
That framing is why I have been following the public conversation around background agents. I do not see it mainly as a product category. I see it as vocabulary for something many teams will have to design anyway: how agents fit into real operating loops.
Background is not enough
There is a difference between “an agent running in the background” and a background agent.
An agent running in the background is mostly a runtime detail. It may keep working after I leave the chat. It may take longer tasks. It may open files, call tools, and eventually return with an answer.
A background agent needs more structure than that.
It needs to know why it started, what work it is allowed to claim, what sources it can inspect, what it must never touch, what artifact it should produce, and where it has to stop. Without that, background execution can become a faster way to create unreviewed work.
This is the part I care about. The value is not hidden effort. The value is reviewable momentum.
A good background agent should make the next human decision easier. It should not try to make the decision disappear.
The loop I keep building toward
For my own work, the pattern is becoming fairly clear.
There is a source of truth. Usually a GitHub Project, an issue, a note, a repository, or a scheduled check. The agent reads that source, claims one bounded piece of work, loads the relevant context, creates an artifact, runs checks, and hands the result back through a channel I already use.
On this site, for example, the content worker does not wake up and decide what I should write about. It reads a project board. It only touches issues that are explicitly marked ready. It checks the repo, reads the brief, drafts one Journal post, creates any required visual support, prepares LinkedIn copy, runs the build, opens a draft PR, and stops.
That last verb matters.
It stops before publication. It stops before merge. It stops before pretending that taste, judgment, and public positioning have been delegated away.
The same pattern applies to product work. In IrishTalents, a safe agent workflow might inspect public-safe backlog items, summarize aggregate coverage gaps, prepare a content brief, or propose a product cleanup task. It should not expose private data, invent market claims, or publish conclusions from weak evidence. The useful work is bounded: gather context, structure the next step, produce something reviewable, and leave a trace.

The bottleneck moves
The theory of constraints is a useful lens here.
When agents make one part of the system faster, the bottleneck moves somewhere else. If drafting becomes cheap, review becomes the constraint. If code generation speeds up, integration and testing become the constraint. If research summaries arrive every morning, prioritization becomes the constraint. If five agents can produce ten artifacts overnight, attention becomes the constraint.
That is not a reason to avoid agents. It is a reason to design the loop honestly.
More generation does not automatically mean more progress. Sometimes it means more unresolved work sitting in pull requests, more drafts waiting for taste, more tickets that look complete but still need a decision, and more context for a human to reload.
I am less worried about whether agents can produce things. They clearly can.
I am more interested in whether the surrounding system can absorb what they produce.
What humans still need to own
Some work can move to agents. Some work should not.
Agents can do repeatable operating work: check a queue, inspect a repository, compare files, summarize safe data, draft a first version, create a diagram, run a build, prepare a pull request, or point out that a task is blocked.
Humans still need to own the constraints.
What should this system optimize for? What is too risky to automate? Which data can be used? Which claim is safe to make publicly? What is the right tone for this article? Which product trade-off is acceptable? Is this PR worth merging now, or is it just more work that looks finished?
Those questions are not ceremony. They are the control layer.
A background agent without human-owned constraints becomes a productivity-shaped liability. It can create plausible work faster than the organization can judge it. It can also make weak processes look more automated without making them healthier.
The practical design questions
When I think about background agents now, I do not start with “how autonomous can this be?”
I start with smaller questions:
- What event should trigger the agent?
- Which queue or source of truth decides eligibility?
- What is the smallest useful artifact it can produce?
- Which tools are read-only?
- Which actions need explicit human approval?
- What evidence should appear in the handoff?
- Where does the agent stop?
Those questions make the system less theatrical and more useful.
They also make it easier to notice when the process is not ready for an agent. If the queue is unclear, the agent will claim the wrong work. If the brief is vague, the output will be vague. If nobody has time to review, more automation will only build a pile. If the permissions are too broad, a small task can create a large blast radius.
The hard part is not always the model. Sometimes the hard part is admitting that the operating system around the model is still immature.
The version I want
I want background agents that act like careful operators inside a system I understand.
They should be able to wake up from a schedule or event, read the right context, do a bounded job, verify what they changed, and package the result so I can make a decision. They should make work easier to review, not harder to audit. They should create momentum without stealing ownership.
That is a quieter vision than agent-run companies or agents replacing whole teams. It is also more believable.
The next useful step for agents is not simply more autonomy. It is better integration with humans, tools, queues, permissions, logs, and review habits.
If you are thinking about background agents, human-in-the-loop workflows, or where the bottlenecks move when AI makes part of the work faster, I would be happy to compare notes.
I suspect the important work is not asking agents to do everything.
It is designing the systems where they can do the right things, at the right time, with humans still responsible for the consequences.